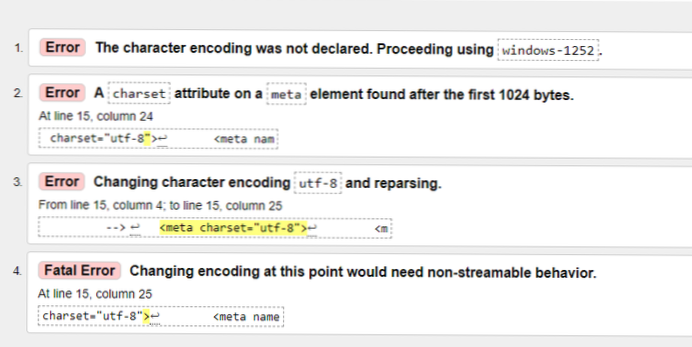
- How do I get rid of UTF-8 error?
- What is UTF8 error?
- How do I change the encoding to UTF-8?
- How is UTF8 stored?
- How do I fix Unicode problems?
- What characters are not allowed in UTF-8?
- What does UTF-8 mean in HTML?
- Why did UTF-8 replace the ascii?
- Is UTF-8 the same as Ascii?
- What is difference between ANSI and UTF-8?
- Why is UTF-8 used?
- What UTF-8 means?
How do I get rid of UTF-8 error?
2 Answers
- use a charset that will accept any byte such as iso-8859-15 also known as latin9.
- if output should be utf-8 but contains errors, use errors=ignore -> silently removes non utf-8 characters, or errors=replace -> replaces non utf-8 characters with a replacement marker (usually ? )
What is UTF8 error?
UTF-8 is the dominant character encoding format on the World Wide Web. This error occurs because the software you are using saves the file in a different type of encoding, such as ISO-8859, instead of UTF-8. There are different solutions you can use to change your file to UTF-8 encoding.
How do I change the encoding to UTF-8?
Click Tools, then select Web options. Go to the Encoding tab. In the dropdown for Save this document as: choose Unicode (UTF-8). Click Ok.
How is UTF8 stored?
When software reading UTF-8 comes across a byte starting with 1, it counts how many 1's follow before encountering a 0. ... So a byte of the form 110xxxxx says the first five bits of a Unicode character are stored at the end of this byte, and the rest of the bits are coming in the next byte.
How do I fix Unicode problems?
The first step toward solving your Unicode problem is to stop thinking of type< 'str'> as storing strings (that is, sequences of human-readable characters, a.k.a. text). Instead, start thinking of type< 'str'> as a container for bytes.
What characters are not allowed in UTF-8?
Note that a byte-order mark (BOM) U+FEFF, aka zero-width no-break space (ZWNBSP), cannot appear unencoded in UTF-8 — the bytes 0xFF and 0xFE are not permitted in valid UTF-8. An encoded ZWNBSP can appear in a UTF-8 file as 0xEF 0xBB 0xBF, but the BOM is completely superfluous in UTF-8.
What does UTF-8 mean in HTML?
charset=UTF-8 stands for Character Set = Unicode Transformation Format-8. It is an octet (8-bit) lossless encoding of Unicode characters. These should shed more light on the understanding in Web Development and Scripting.
Why did UTF-8 replace the ascii?
The UTF-8 replaced ASCII because it contained more characters than ASCII that is limited to 128 characters.
Is UTF-8 the same as Ascii?
For characters represented by the 7-bit ASCII character codes, the UTF-8 representation is exactly equivalent to ASCII, allowing transparent round trip migration. Other Unicode characters are represented in UTF-8 by sequences of up to 6 bytes, though most Western European characters require only 2 bytes3.
What is difference between ANSI and UTF-8?
ANSI and UTF-8 are two character encoding schemes that are widely used at one point in time or another. The main difference between them is use as UTF-8 has all but replaced ANSI as the encoding scheme of choice. ... Because ANSI only uses one byte or 8 bits, it can only represent a maximum of 256 characters.
Why is UTF-8 used?
Why use UTF-8? An HTML page can only be in one encoding. You cannot encode different parts of a document in different encodings. A Unicode-based encoding such as UTF-8 can support many languages and can accommodate pages and forms in any mixture of those languages.
What UTF-8 means?
UTF-8 Basics. UTF-8 (Unicode Transformation–8-bit) is an encoding defined by the International Organization for Standardization (ISO) in ISO 10646. It can represent up to 2,097,152 code points (2^21), more than enough to cover the current 1,112,064 Unicode code points.
![Is it good practice to use REST API in wp-admin plugin page? [closed]](https://usbforwindows.com/storage/img/images_1/is_it_good_practice_to_use_rest_api_in_wpadmin_plugin_page_closed.png)